We’ve used the standard error several times on this blog without going into much detail about it. In simplest possible terms the SE is the range within which we expect a value (typically the mean) to be. Specifically it is the standard deviation of the sample means.
This requires a bit of abstract thought. If you take many samples from a population you will not always get the same mean value. After taking many samples you’ll have a distribution of those means. We are attempting to describe the characteristics of something one step more abstract than the mean. To see a more concrete example refer to the post of efficient estimators.
When we say “the average weight of a baseball player is 200 pounds” we mean that in our sample the average weight is 200 pounds and that we believe this is close to the true average of the population. With the standard error, confidence interval, or credible interval we quantify how close we expect it to be.
Using our baseball player data from a while back, let’s look at how the standard error works in an ideal situation. We know the true mean of the population so let’s take a bunch of random samples and see how often we capture the true value of the mean.
For convenience make the weight its own object:
weight <- tab$weight
Here is the equation that defines the standard error, first in common notation and then as a custom R function.
. . . where s is the sample standard deviation (s2 is the sample variance) and n is the sample size.

se <- function(x) {sd(x)/sqrt(length(x))}
Now we use replicate() and sample() to take 1000 samples of 100.
r <- 1000 size <- 100 samps <- replicate(r,sample(weight,size))
Using the apply() function we get the mean and standard error of each sample.
means <- apply(samps,2,mean) ses <- apply(samps,2,se) se.h <- means+ses se.l <- means-ses
Add up all of the instances where the top of the interval is less than the mean or the bottom of the interval is more than the mean. These are the instances where the standard error has missed the true value.
a <- sum(length(se.h[se.h < 201.6893]),length(se.l[se.l > 201.6893])) 1-a/r 0.709
That’s actually better than we should expect. Keep in mind that the calculation of the standard error relies on us assuming a normal distribution for the population.
So where does the this equation come from?
As you saw before we calculate the standard error as the standard deviation divided by the square root of the sample size or, perhaps more intuitively, the variance divided by the sample size.
We do this because of the Bienayme formula which provides that the sum of the variance of several variables is the same as the variance of the sums of those variables (ie you draw 10 numbers from two populations and add together each pair).
Consider the equation that defines the mean for some data X:
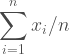
Now imagine a sample of exactly one value. The mean is equal to that value (itself divided by 1) and the variance of those means is exactly the population variance. When we draw a large number of values we can treat our sample as many samples of one (which it is), so then the variance of the sum is the same as the variance of the sample (which is approximately equal to the variance of the population).
This is not a rigorous mathematical proof, of course, the intention is to understand the intuition of why the standard error is the way it is. Personally, I find it comforting to know that the standard error is not produced out of thin air.

