The binomial distribution describes the probabilities that occur when “sampling with replacement” and the hypergeometric distribution describes the probabilities that occur when “sampling without replacement”. Both of them, however, are limited to the behavior of binary events like the flipping of a coin or success and failure. Extending them into multiple dimensions (and thus events that aren’t binary) requires understand exactly what the definitions of the basic distributions mean.
Before reading this post check the posts about the binomial coefficient, the binomial distribution, and the hypergeometric distribution to make sure you can follow along with the notation.
The multidimensional hypergeometric distribution is actually trivial. Let us make one change to how we define it. First there is N which is the population size and n which is the same size. Second there is K1, the size of the first group, and k1, the number we want from the first group along with K2 and k2 defined the same way along with K3 and k3 . . . and so on.
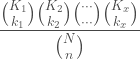
This is exactly the same as the equation for basic hypergeometric distribution, just parametrized differently. If we treat “success” and “failure” as simply two groups the equivalency is obvious:

In both cases we define how many ways there are to “correctly” pick from each group until we have all of the groups accounted for and multiply those combinations together then divide by the number of possible combinations.
Now for the binomial distribution. We took a look at where the defining equation comes from recently.
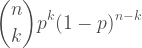
To see how this generalizes into multiple dimensions we start by expanding the binomial coefficient.

Now we will rename the parameters so that we can see what happens as the dimensions are added. Rather than defining “tails” in terms of “heads” (which is what is meant when we see n-k) everything gets its own name. Now there is n the sample size, kx the number we want from each group, and px the probability of picking a each group.
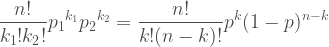
It is then natural to see that the distribution generalizes in to multiple dimensions like this:
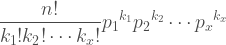
We can thus define sampling with replacement for any number of groups just by adding new terms as needed.



