Here’s a question for you. A line of musketeers, ten abreast, is firing on the enemy. Each man has a 10% chance of hitting his target at this range. What is the probability that at least one of them will hit in the first volley? This is a traditional sort of problem in logic and probability. To some people it seems as though there ought to be a 100% chance since that’s 10 times 10 but some further thought reveals that since there is some chance of each of them missing there must be some chance of all of them missing.
We calculate the result 100% minus the probability of each missing (90%) to the power of the number of musketeers (10).
1-(.9^10)
0.651
So about an 65% chance of at least one of them hitting.
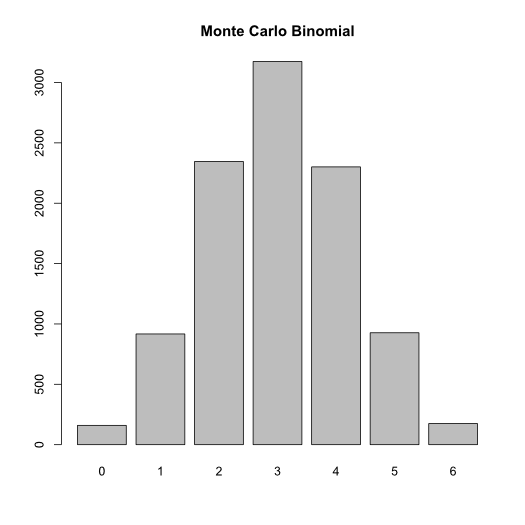
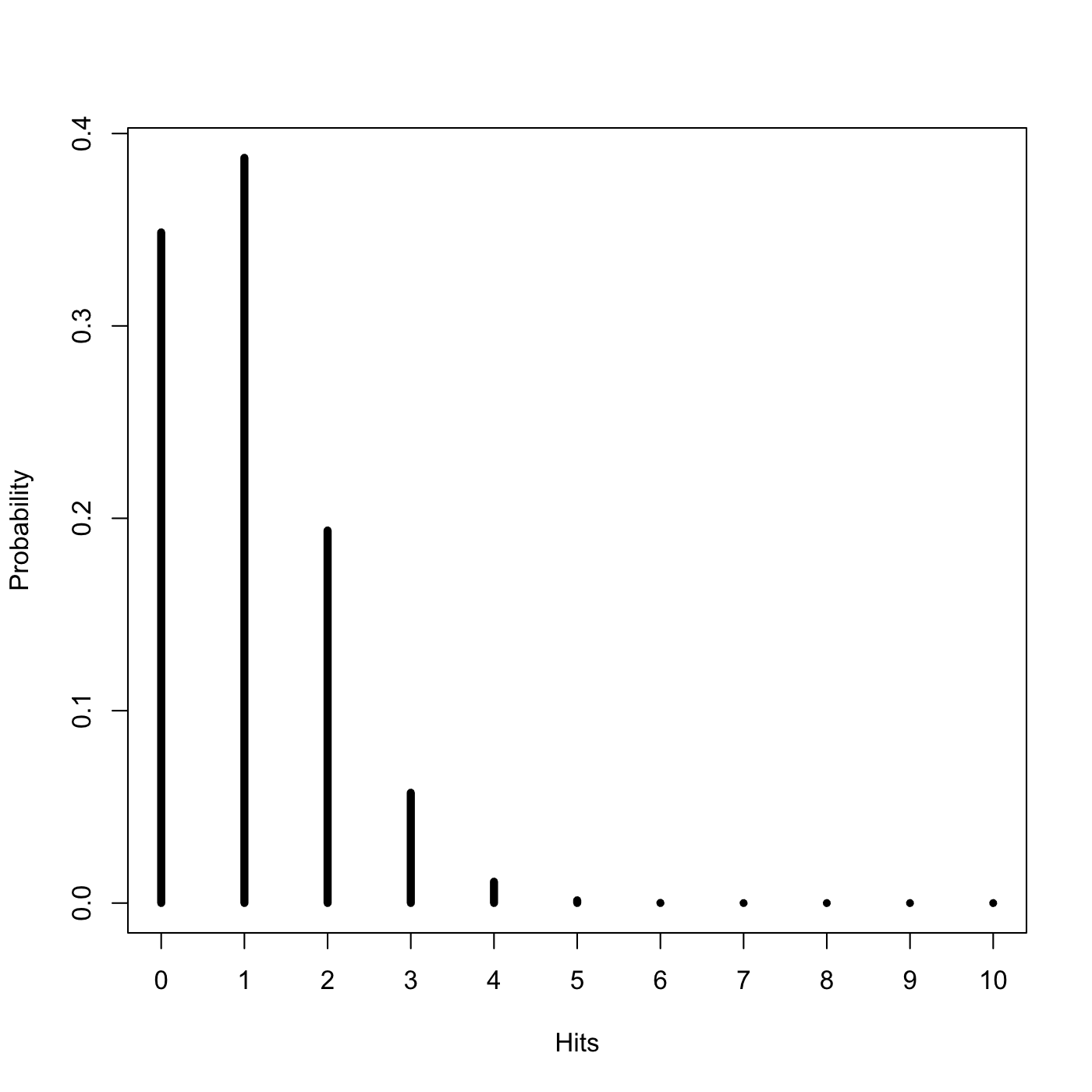
That’s not a super informative result since it doesn’t tell us anything like what the most likely number of hits is. Consider this however: Shooting at a target is a Bernoulli trial, just like the flipping of a coin. It has exactly two outcomes, hit or miss, and particular probability. Thus the successes of the musketeers ought be following a Binomial distribution (both logically and because I have a theme going). Indeed they do, the distribution of their volleys should look like this:

We see immediately that the most likely outcome is that 1 of them will hit and that is almost inconceivable that more than 4 of them will hit. Musketeers were not terrible efficient military machine, although they were quite deadly en masse.
Say you are the commander of this line and you’re not happy with the atrocious accuracy of these soldiers. You want a 90% of getting at least one hit. How much better do the musketeers have to be?
Thanks to computers the easiest method, and most general, is to just test many possible values.
## Many candidate values of q, the probability of a miss
q <- seq(.9,.5,-.01)
## The corresponding values of p.t the total probability
## of a hit for the musketeers as a group.
p.t <- 1-(q^10)
## We set a equal to the smallest values of p.t that is equal
## to or greater than 0.9 and then check out what is on that
## line.
dat <- data.frame(q,p.t)
a <- min(dat$p.t[p.t >= .9])
dat[dat$p.t==a,]
q p.t
12 0.79 0.9053172
Recalling that for Bernoulli trials p = 1 – q we conclude that the probability of hitting on each shot it 0.21, or a 21% chance. The soldiers need to double their accuracy. You will also notice that if you make a binomial distribution with the new value of p the most likely outcome is now that two of the soldiers will hit.
For safety’s sake lets work out the analytical solution to the problem in order to check out answer.
.9 = 1-(x^10)
.9+(x^10) = 1
x^10 = .1
x = .1^.1
x = .794
1-.794
.206
Yep, that’s basically the same answer.
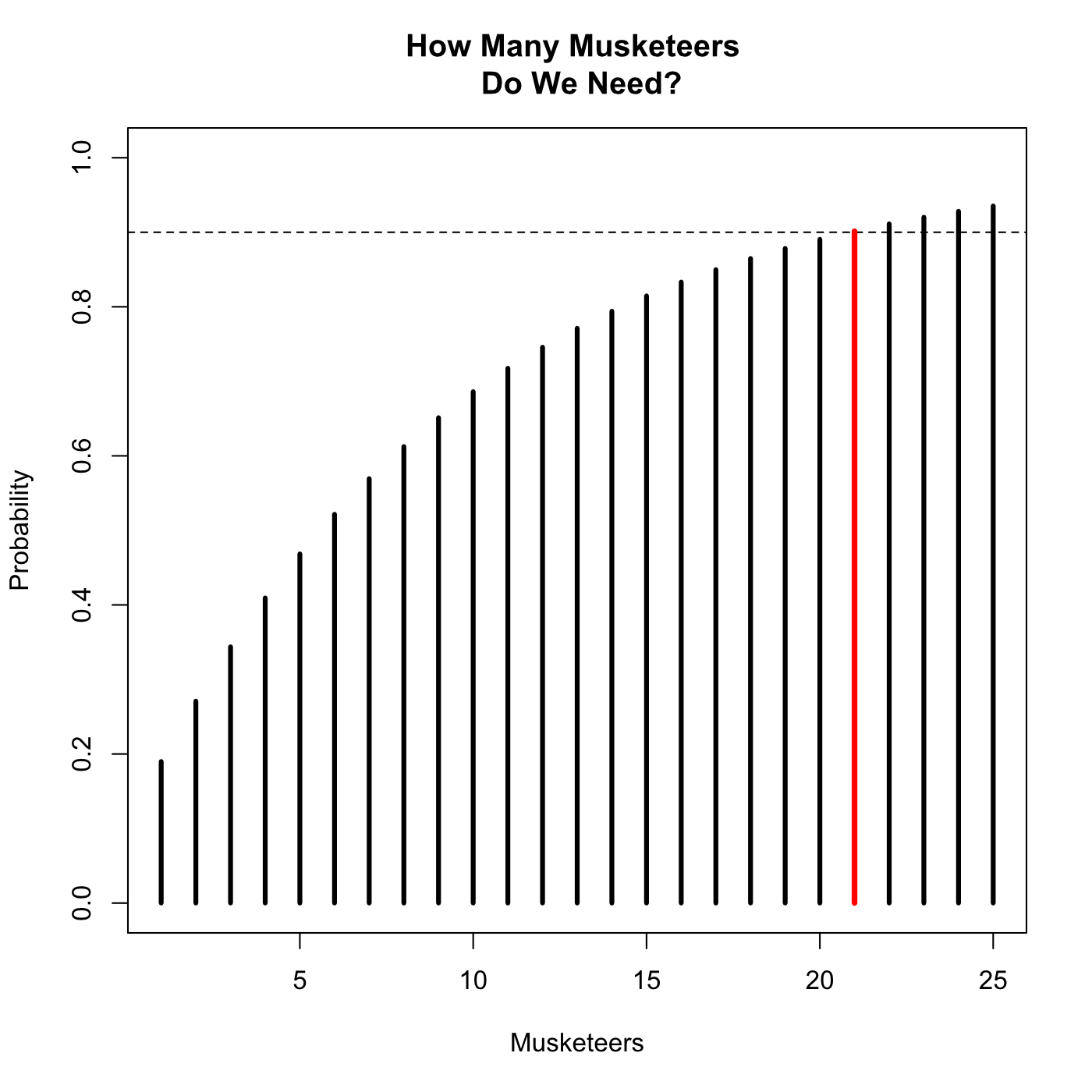
What if we tried to solve our problem the other way around? Historically musket lines were enormous and successful in part because it was easier to hand a musket to ten people than train one person to be a really good shot with them. How many musketeers need to be on the line to have a 90% that at least one of them will hit?
We could, of course, use the same method as we did before and simply recalculate for larger and larger numbers of musketeers. If we did we would end up with a cumulative geometric distribution a relative of the binomial.

Like the binomial the geometric distribution is discrete, it has values only at whole numbers.
If there is one musketeer there the probability of hitting is 0.100, if there are two the probability is 0.190 (not quite double), if there are three the probability is 0.271, and so on. Eventually, with 21 musketeers, the probability rises to fully 0.902 and we’re done.
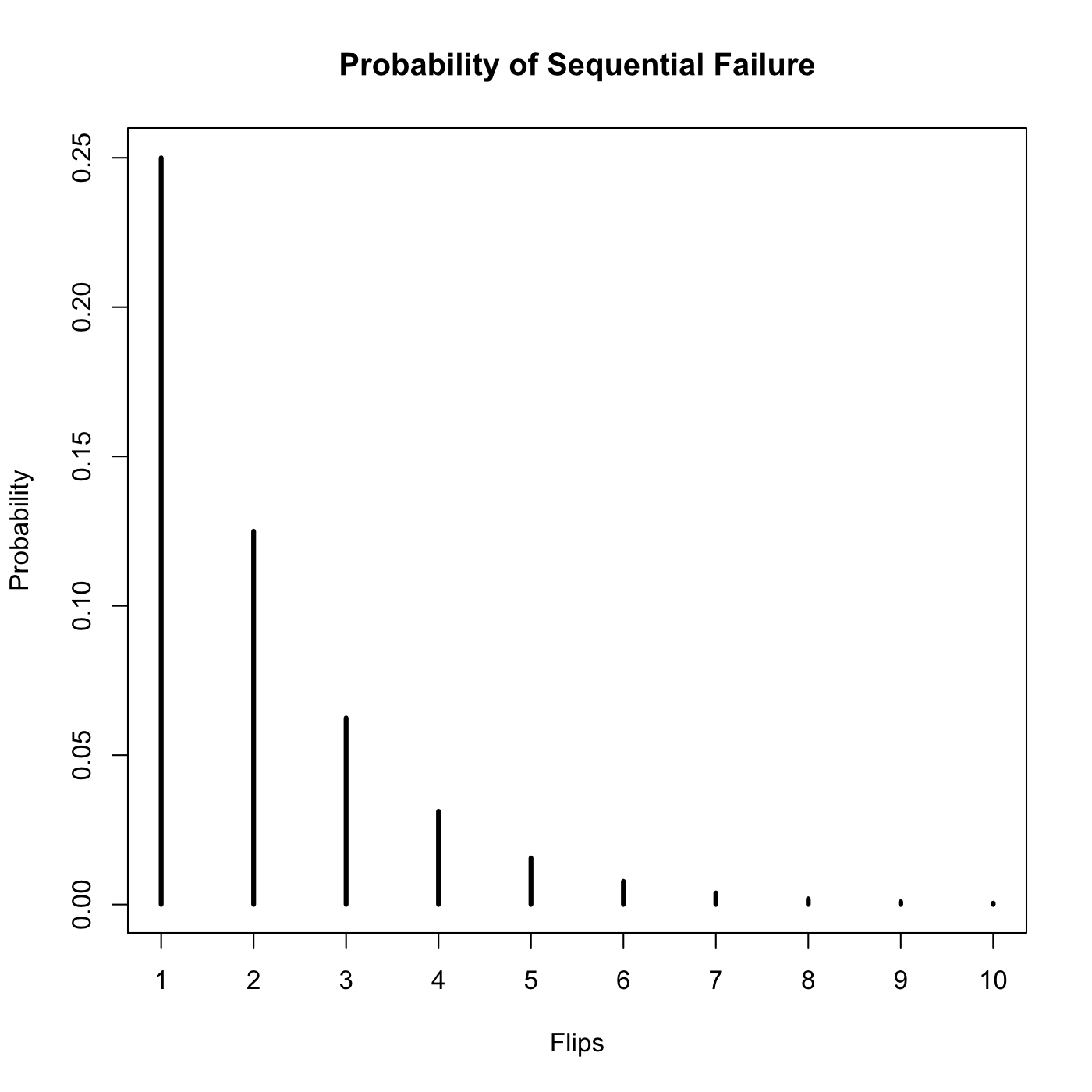
The plain geometric distribution itself is the probability that it will take N trials to get a success. Here is the flipping of a fair coin:

The probability of getting Tails on the first flip is 50%, the probability of getting Tails on the first flip and the second flip is 25%. This is why the cumulative distribution shows us the probability of getting a heads.
The code for our graphics in this post.
The binomial distribution. This is very simple but I include it because the xaxp argument is so rarely used. R creates tick marks automatically but not the ones I wanted in this case. The argument tells R the smallest tick mark to label, the largest one, and the total number of tick marks.
Hits <- 0:10
Probability <- dbinom(0:10,10,.1)
volley <- data.frame(Hits,Probability)
plot(volley,type='h',lwd=5,xaxp=c(0,10,10))
The cumulative geometric distribution.
## When the code \n is used in a string R will read it as creating a new line.
plot(pgeom(1:25,.1),type='h',lwd=3,
main='How Many Musketeers \n Do We Need?',xlab='Musketeers',ylab='Probability',
ylim=c(0,1))
## Create a horizontal dashed line.
abline(h=.9,lty=2)
## Draw a red line that covers column 21.
segments(21,0,21,0.9015229,col='red',lwd=3.5)