Welcome back to my irregular series Weird Facts from MTG JSON, using data made available by Robert Shultz on his site.
In Magic: The Gathering every card requires a resource called “mana” in some amount in order to be used. The converted mana cost (abbreviated cmc) can be can zero or any natural number. Now we might wonder how those costs are distributed among the more than 13 thousand unique cards in the game.
Naively there are a lot of valid possibilities but anyone familiar with the game will be know that the vast majority of cards cost less than five mana. I expect they would be hard pressed to say with confidence which cost is the most common, though. Let’s check it out!
First the data itself:
library(rjson)
source("CardExtract.R")
## Read the data into R.
AllSets <- fromJSON(file="AllSets.json")
## Filter all of it through the extraction function,
## bind it together and fix the row names.
l <- lapply(AllSets,extract.cards)
AllCards <- AllCards[AllCards$exp.type != "un",]
AllCards <- do.call(rbind.data.frame,l)
rownames(AllCards) <- 1:length(AllCards$cmc)
Now we take three pieces of information we need, the name, the cost, and the layout for each card. We get rid of everything except “ordinary” cards and the squeeze out everything unique that remains so reprints don’t affect our results.
name <- AllCards$name cmc <- AllCards$cmc lay <- AllCards$layout dat <- data.frame(name,cmc,lay) dat <- dat[dat$lay == 'normal' | dat$lay == 'leveler',] dat <- unique(dat)
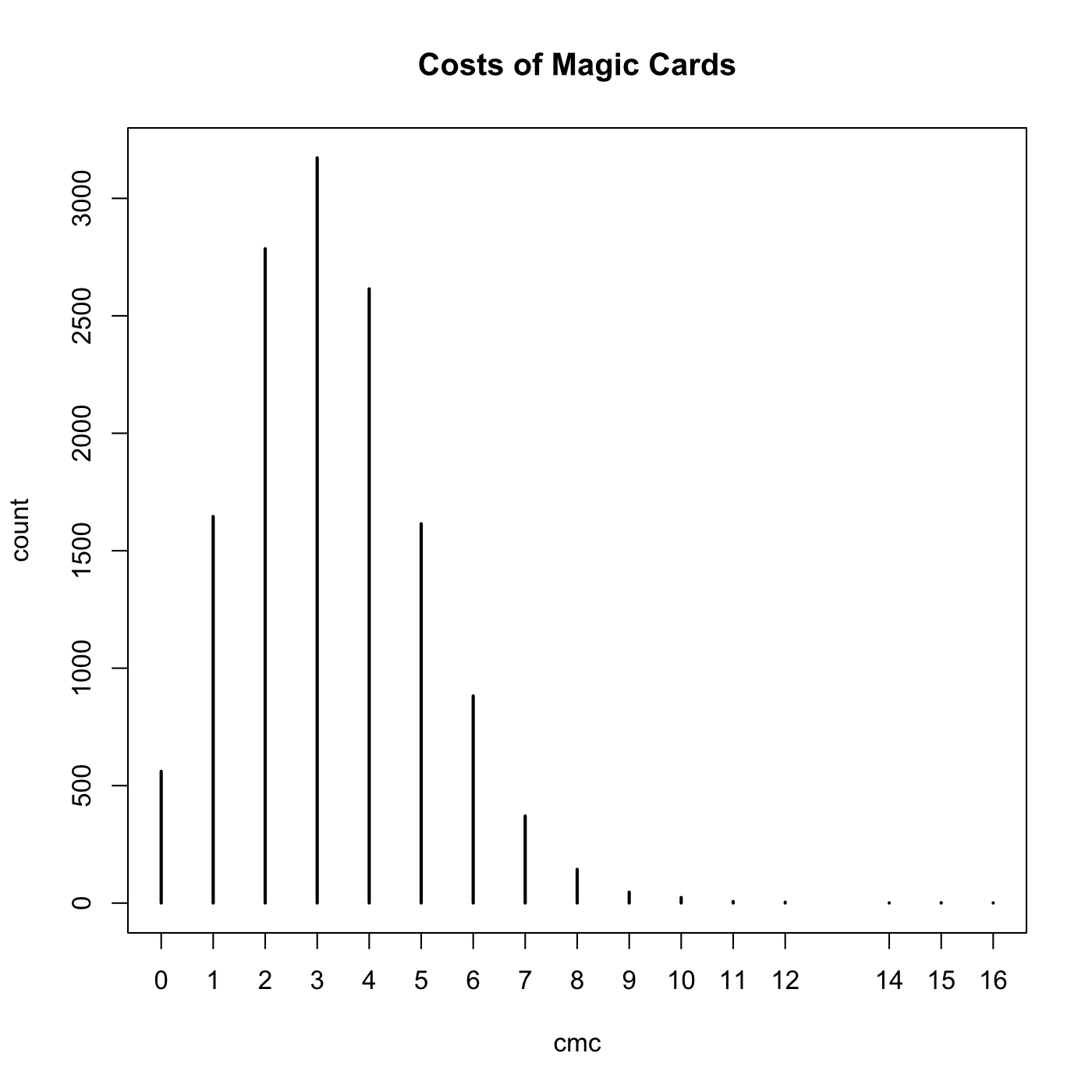
Here’s where something very interesting happens so bear with me for a second. Let’s plot the counts for each unique cmc.
plot(table(dat$cmc), ylab='count',xlab='cmc', main='Costs of Magic Cards')
If you read Wednesday’s post where we recreated the London Blitz this should look very familiar. That’s right, the costs of Magic cards follow a Poisson distribution. We can add some points that show the appropriate Poisson distribution.
m <- mean(dat$cmc) l <- length(dat$cmc) comb <- 0:16 plot(table(dat$cmc), ylab='count',xlab='cmc', main='Costs of Magic Cards \n Poisson In Red')
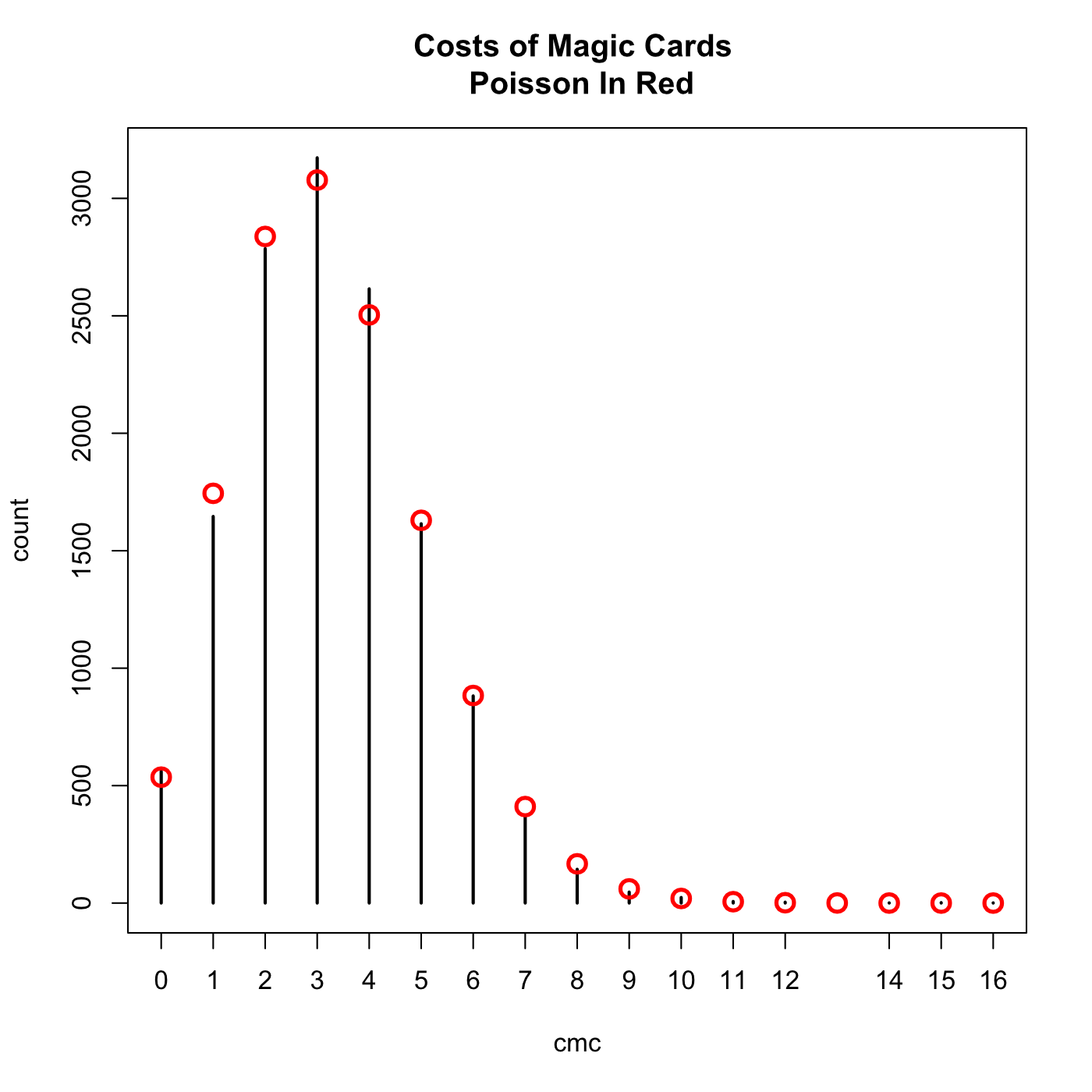
Its a ridiculously good fit, almost perfect. What is going on exactly? I mean I doubt they did this deliberately. When we last saw the Poisson distribution, and in almost every explanation of it you will ever find, the Poisson is the result of pure randomness. Are the design and development teams working blindfolded?

(Image from “Look At Me I’m The DCI” provided by mtgimage.com)
(Art by Mark Rosewater, Head Designer of Magic: The Gathering)
Nope. The secret is to think about where exactly the Poisson distribution comes from and forget its association with randomness. It requires that only zero and the natural numbers be valid possibilities and that a well defined average exists. Although Magic has never had a card which cost more than 16 mana there’s no actual limitation in place, high costs are just progressively less likely.
I expect that what we are seeing here is that the developers have found that keeping the mean cost of cards at around 3.25, in any given set, makes for good gameplay in the Limited format. Because they also want to keep their options open in terms of costs, a creature that costs more than 8 mana is a special occasion, the inevitable result is a Poisson distribution.