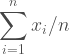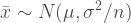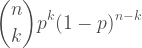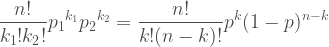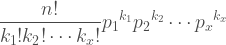The z-test, like the binomial test, is a way of testing a hypothesis. It is not a very common form of hypothesis test because it requires us to have a great deal of information we do not usually have but it is an illustrative example that will serve as a stepping stone on the way to the t-test which has more practical applications.
In order to perform a z-test we need to know the the variance of the population that the sample is drawn from. This is not an easy thing to determine in practice.
Many IQ tests are tuned to produce a precise degree of variance when tested on the general population, one of the few somewhat real world examples of an instance where we can use a z-test. Imagine that we are using a test that is designed to have a standard deviation of 10 and a mean of 100. We give this test to 11 people who are supposed to be very clever. Their mean score is 107. The standard error should be:
se <- 10/sqrt(11) se 3.015113
Now that we know the standard error we can calculate the z-score in order to draw conclusions about the data we then determine. This is a form of normalization except we are adjusting for variability in the means rather than variability in the data itself. Thanks to the central limit theorem we believe that the mean values of a sample will follow a normal distribution.
z <- (107-100)/se z 2.321637
In a literal sense the z-score is how many standard errors from the population mean our sample mean is. This value is now compared to the standard normal distribution (also know as the z-distribution hence the name!) exactly the way we did with the binomial distribution.
1-pnorm(z) 0.01012624
So there is about a 1% chance of getting a value as large or larger than the one we found and about a 2% chance of getting a value as extreme or more extreme. Generally we would be comfortable concluding that these people are, in fact, better at taking IQ tests than most people.